



















Businesses are increasingly recognizing that data lakes are a surefire way to leverage previously unusable data and break down data silos that many companies are struggling to overcome. In this article, we will explain what a data lake is and its architecture, highlight the benefits of implementing a data lake in your organization, provide a step-by-step guide to building a data lake, and showcase several high-end organizations that have turned to data lakes for further success. Now read on!
According to Gartner, “a data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores”.
In simple terms, a data lake is a repository that, due its scalable and open architecture can hold different types of data, such as:
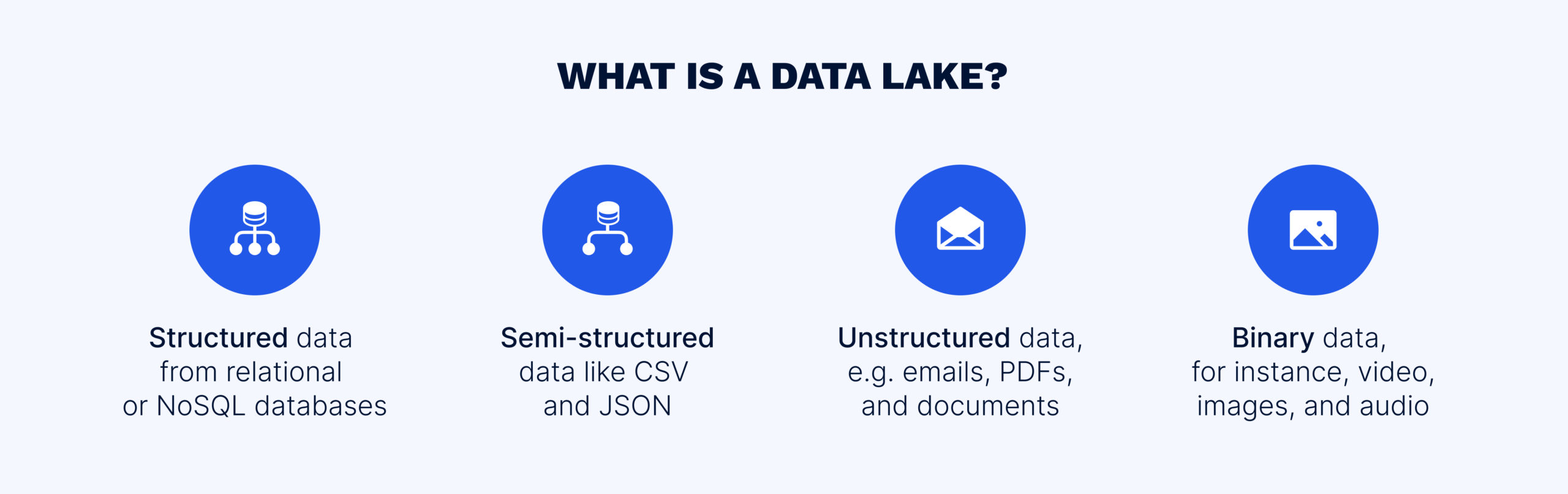
Traditionally, companies hosted data lakes on premises; now, businesses are shifting towards cloud-based data lakes due to their scalability, low cost, and flexibility.
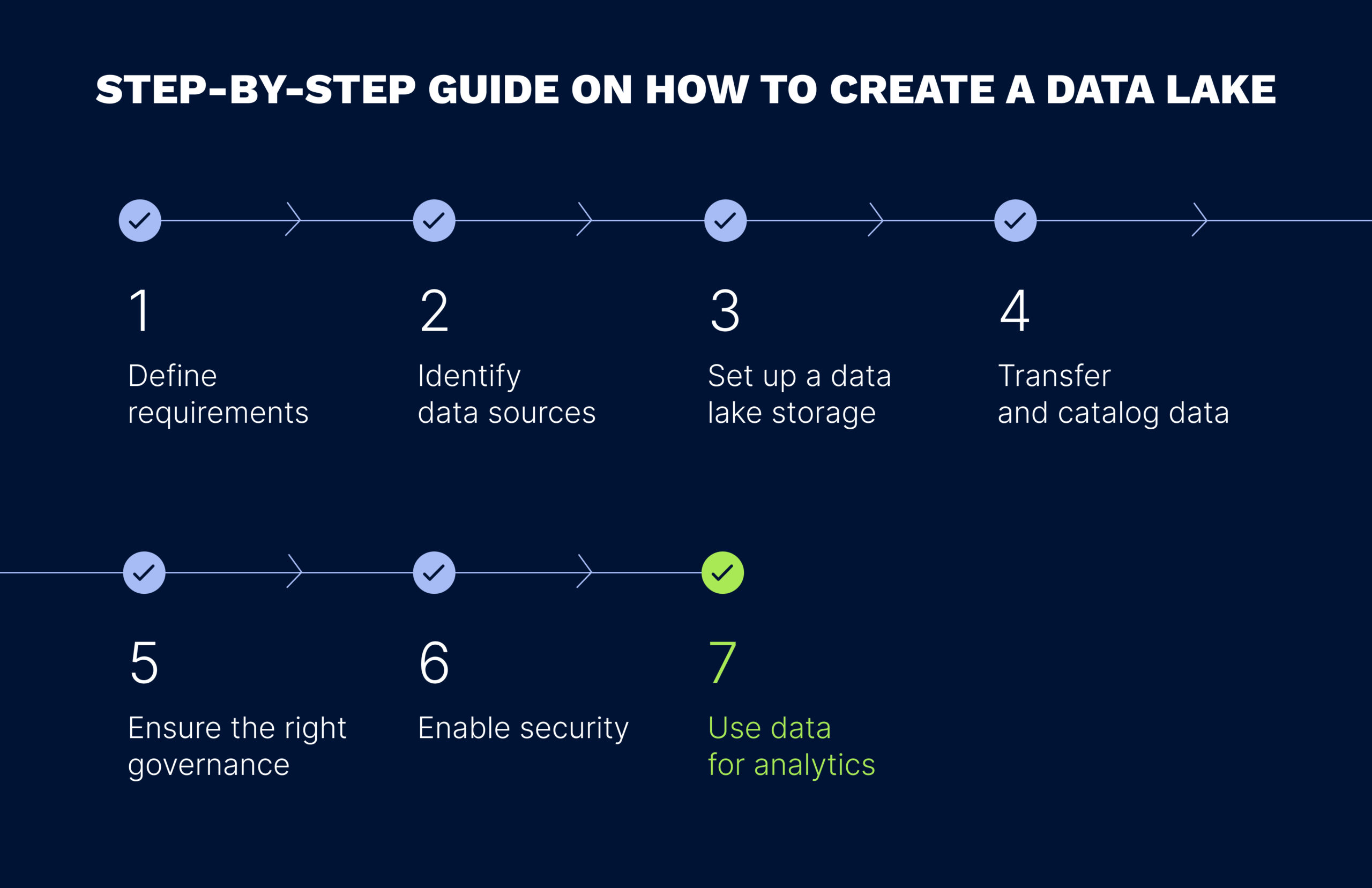
Data lakes typically feature a multi-layered architecture, with each layer playing an important role in the data lifecycle. However, data lake architectures vary from organization to organization, depending on business needs and technical requirements. The following are the core layers of a typical data lake architecture.
The raw data layer, also referred to as the ingestion layer, is the first point at which data enters the data lake. Here, raw data is collected from different external sources, such as IoT devices, social media platforms, and data streaming devices, and is ingested either in real-time or in batches. Real-time ingestion means that data is captured as it is created and ingested continuously, which is extremely useful for collecting data from sensors or streaming data. Batch ingestion means that data is collected in batches, at scheduled intervals, and is used for routine data collection tasks. Once ingested, data is stored in its native format with minimal processing.
The standardized data layer is optional and is used to transfer data between the raw and cleansed data layers. In this layer, data is converted into a standardized format to make it suitable for processing and cleansing. This transformation typically involves changing data structure, file formats, and encoding to ensure compatibility with other tools and systems.
In the cleansed (or curated) data layer, raw data is transformed into consumable datasets that are prepared for further analysis. Data processing tasks such as cleansing, denormalization, and the consolidation of different objects are executed. Data cleansing removes impurities and corrects erroneous data; denormalization is the merging of data from normalized tables back into a single table to retrieve data quickly and improve query performance; and object consolidation involves determining the representations of identical objects in a database. As a result, data, stored in files or tables, is made uniform in terms of format, type, and encoding, and is thereby ready for consumption.
At the application level, the curated data is given a logical structure and is transformed into usable information with the help of various analytical tools and processes. Business logic is then applied to align data with business requirements and make it consumable by different applications. Therefore, users can send queries to the relevant data to prepare datasets for ML models and AI-based solutions and for use in various analytical tools. Data here can also be used for feeding operational applications used in the company so that the raw data becomes meaningful and powers data-driven internal solutions. In other words, it is a shift from storing data to utilizing it, thereby creating business value.
The sandbox data layer is an optional final layer in the architecture that provides a controlled environment for running advanced analytics without compromising the main data lake. Data scientists and analysts can explore the data, look for patterns and correlations, and enrich the data they are working with by incorporating additional information or resources, such as external datasets or statistical models. This layer allows for experimentation while ensuring that the data remains secure and unchanged.
There are several benefits of creating a data lake for your organization that are worth noting. Here are five reasons why you should consider implementing this type of data repository.
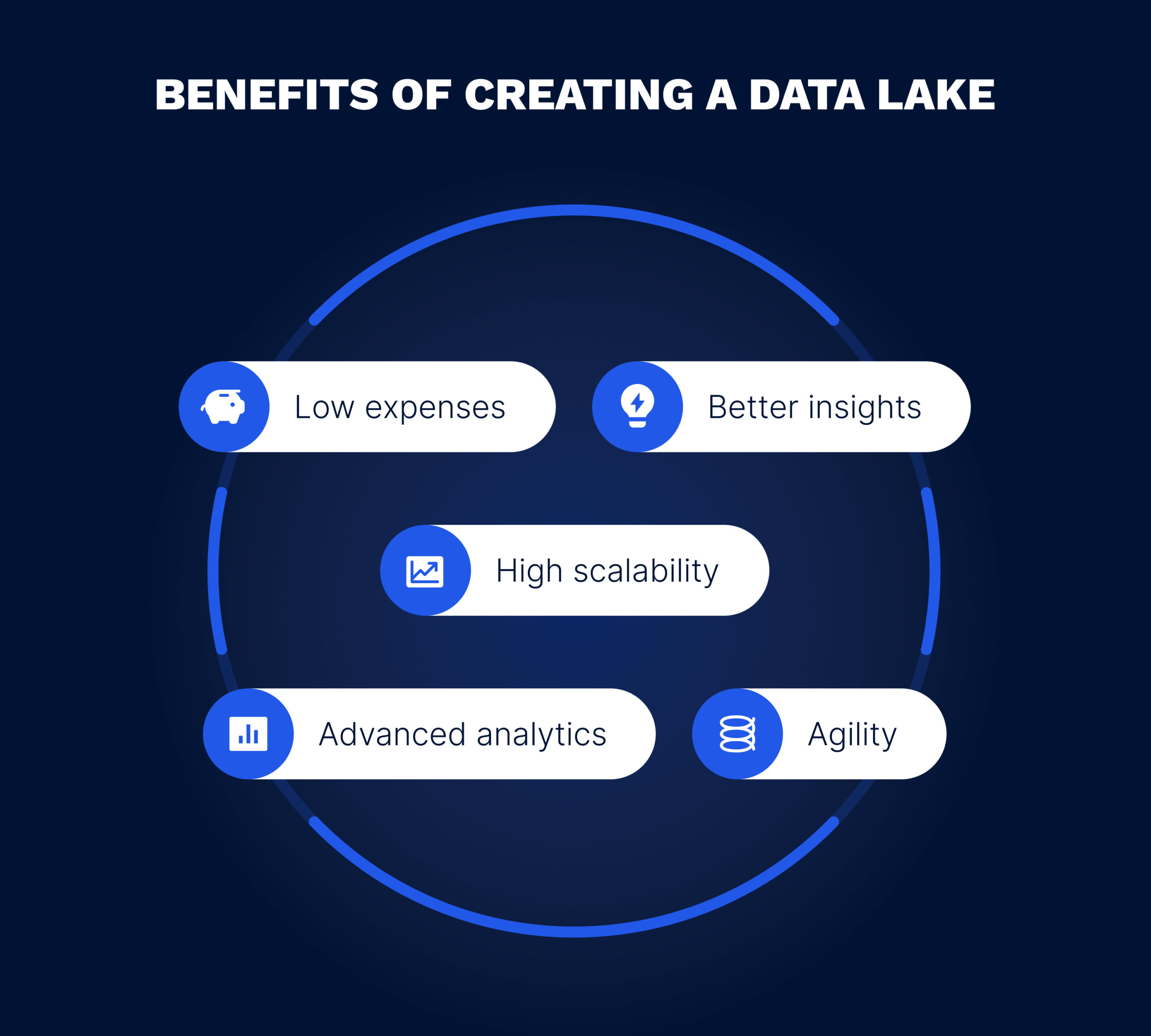
The highest level of data lake scalability is ensured by a well-designed data lake architecture, enabling data lakes to handle large volumes of data and grow with your business. This is achieved by setting up the right data storage and processing systems, as well as establishing efficient data access patterns and transformation pipelines. A well-designed data lake can easily accommodate increasing data volumes and user activity, without requiring proportional investments in hardware or infrastructure and without becoming a bottleneck for the company.
A data lake is a more cost-effective option than other data storage solutions such as data warehouses. They don’t require extremely expensive hardware and use open-source technologies for data management, reducing the overall cost of maintaining data. According to Mordor Intelligence, the overall market size for data lakes is expected to grow from USD 13.74 billion in 2023 to USD 37.76 billion by 2028, making it a worthwhile investment for businesses.
Data lakes are highly customizable, allowing you to configure them for any data model, structure, or application. This means they can be easily adapted to meet changing business needs without requiring any significant changes to the infrastructure.
Data lakes enable the collection and analysis of structured, semi-structured, and unstructured data. This allows for the performance of advanced analytics, such as predictive or prescriptive analytics, leading to data-driven decisions that can help streamline operations and adapt to market changes.
According to ChaosSearch, 87% of businesses that employ a data lake approach report that it has improved the decision-making in their companies since all their data is stored in a single repository that provides a comprehensive view of the business. Data lakes help identify patterns, trends, and correlations that would be difficult, or even impossible to detect with traditional data storage solutions.
Multiple companies are currently building a data lake from scratch to control costs and enhance business agility. Here are several outstanding examples of how data lakes are being used by enterprises across diverse industries.

Sisense makes business intelligence simple and accessible for organizations of all sizes. Its powerful analytics applications, driven by artificial intelligence and machine learning, help customers turn data into insights and actions.
With a rapidly growing customer base that generates over 70 billion data records, Sisense has taken certain data lake creation steps and built a robust and scalable cloud-based data lake on Amazon Web Services. They use Amazon Athena for analytics, Amazon Kinesis for real-time streaming data, and Amazon S3 object storage, which together enable Sisense to effectively manage data at scale and generate valuable insights for their customers.
With more than 131 million riders worldwide, Uber needs to efficiently deliver safe and reliable rides. To do this on such a scale, the ride-sharing giant relies on a big data strategy.
After deploying a cloud-based data lake, Uber has reaped many benefits: reduced costs, automated processes, improved customer experience, and increased revenue. Access to insights from massive amounts of real-time data is now fueling Uber’s growth.
As the world’s leading streaming service with over 200 million members, Netflix collects, analyzes, and explores enormous amounts of data every day to attract and retain customers.
Its cloud-based data lake solution enables it to manage different data types for business use, which has helped Netflix improve the customer experience, scale quickly, and significantly boost profits.
Airbnb’s online marketplace connects hosts and travelers worldwide. To power their website and mobile apps that process vast amounts of data, Airbnb has built a robust cloud data lake architecture.
This has enabled the company to efficiently harness data, optimize performance, and increase transaction speeds. Armed with useful insights from the data, Airbnb has dramatically grown its business and income.
Building an effective data lake is a strategic move with numerous benefits for organizations. By using a data lake as a central repository for processing, storing, and analyzing data in its native format, businesses can gain valuable insights and make informed decisions. The flexibility and cost-effectiveness of data lakes make them an attractive storage solution for organizations of all sizes. With more and more leading organizations embracing data lake solutions, now is the time for your company to implement this game-changing technology. To ensure a smooth implementation, contact our experts. With their guidance, you can effectively organize your data and benefit from its full potential.
Blog

























Our team would love to hear from you.
Fill out the form, and we’ve got you covered.
What happens next?
San Diego, California
4445 Eastgate Mall, Suite 200
92121, 1-800-288-9659
San Francisco, California
50 California St #1500
94111, 1-800-288-9659
Pittsburgh, Pennsylvania
One Oxford Centre, 500 Grant St Suite 2900
15219, 1-800-288-9659
Durham, North Carolina
RTP Meridian, 2530 Meridian Pkwy Suite 300
27713, 1-800-288-9659
San Jose, Costa Rica
C. 118B, Trejos Montealegre
10203, 1-800-288-9659

