



















With data lakes, companies can collect data from all available sources and use it to their profit. In this article, we will explain what data lakes are, their tools and technologies, how they differ from data warehouses, what data lake architecture is, and the benefits and challenges of implementing data lakes.
Gartner provides the following data lake definition: “a data lake is a concept consisting of a collection of storage instances of various data assets. These assets are stored in a near-exact, or even exact, copy of the source format and are in addition to the originating data stores.” Simply put, a data lake is a storage environment that holds any type of data, structured, semi-structured, and unstructured, from any source.
Data lakes emerged as a response to a request for storing and processing unstructured data, such as images, videos, audio, etc., which had been impossible with data warehouses. In data lakes, information can be stored as-is, in its original form, and without predefined schemas. Each data component has a unique identifier and is tagged with metadata. This makes it possible to turn raw data into organized datasets, preparing it for further analysis. Data lakes can be employed for real-time analytics, ideation, and Big Data processing.
Why data lake? The name of this repository has a reason. Data fills data lakes from different sources — IoT, social media, web and mobile apps, databases, etc. — just like an actual lake is filled from multiple tributaries.
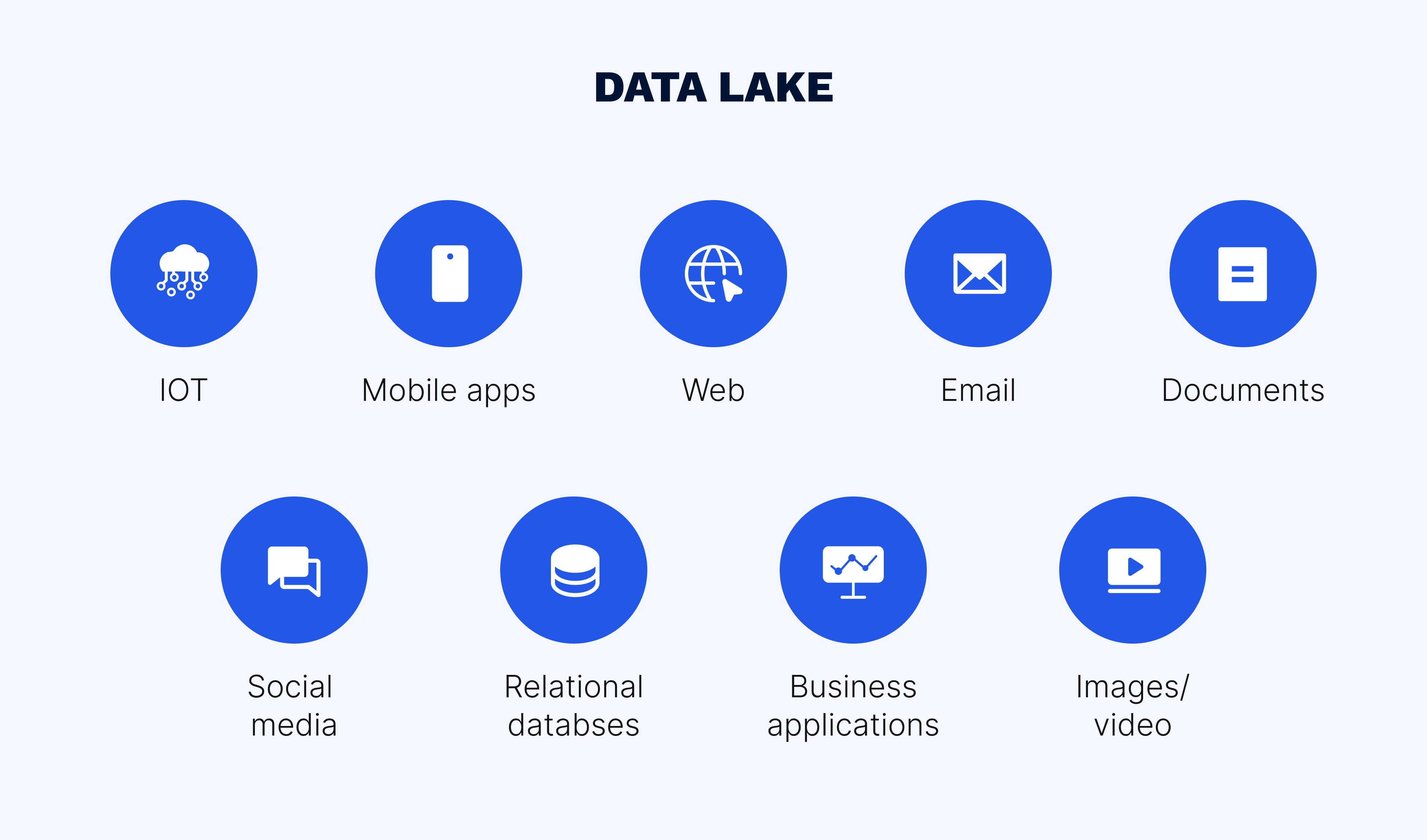
There are many data lake examples in various industries. In marketing, for instance, the harnessed data can be processed and analyzed to provide a 360-degree view of the customer and create super-personalized campaigns. Healthcare, urban science, cybersecurity, finance and banking, logistics, and so on — any industry that requires access to vast amounts of data can find data lakes a profitable endeavor.
Data lakes are built using different frameworks, and each of them includes technologies for data ingestion, storage, processing, accessing, analyzing, and preparing. The following open-source platforms are some of the most popular ones.
Data lakes are often associated with Hadoop, as it was the first framework that allowed working with large volumes of unstructured information. Apache Hadoop consists of the following modules for working with data: Hadoop Common, HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), and Hadoop MapReduce (a distributed computing algorithm). It is built on clusters and allows users to manage big datasets by splitting up large tasks across different nodes.
Apache Spark is used as a processing engine by many data lake architectures, providing companies with a framework for data refinement, machine learning, and other purposes. It consists of several technologies: Spark SQL, Spark Core, MLib, and more. Spark uses RAM to process data, unlike Hadoop MapReduce, which uses a file system. Spark performs faster than MapReduce and is easy to use.
There are different vendors that provide tools for building data lakes. These are some of the well-known solutions:

All these tools may be similar in features but have different structures. For example, Azure data lake architecture, as well as Amazon S3, has a hierarchical directory structure providing high-performance data access.
There are also buildup systems that can perform as engines for these solutions. For instance, Amazon, Google Cloud, or Azure platforms can be powered by Snowflake data lake architecture which has storage, computing, and cloud services layers that can scale independently from one another. It is possible to use several tools at once to provide better performance, ease of integration, and scalability.
Data lakes and data warehouses are both designed to store data, but have different requirements, structures, and purposes.
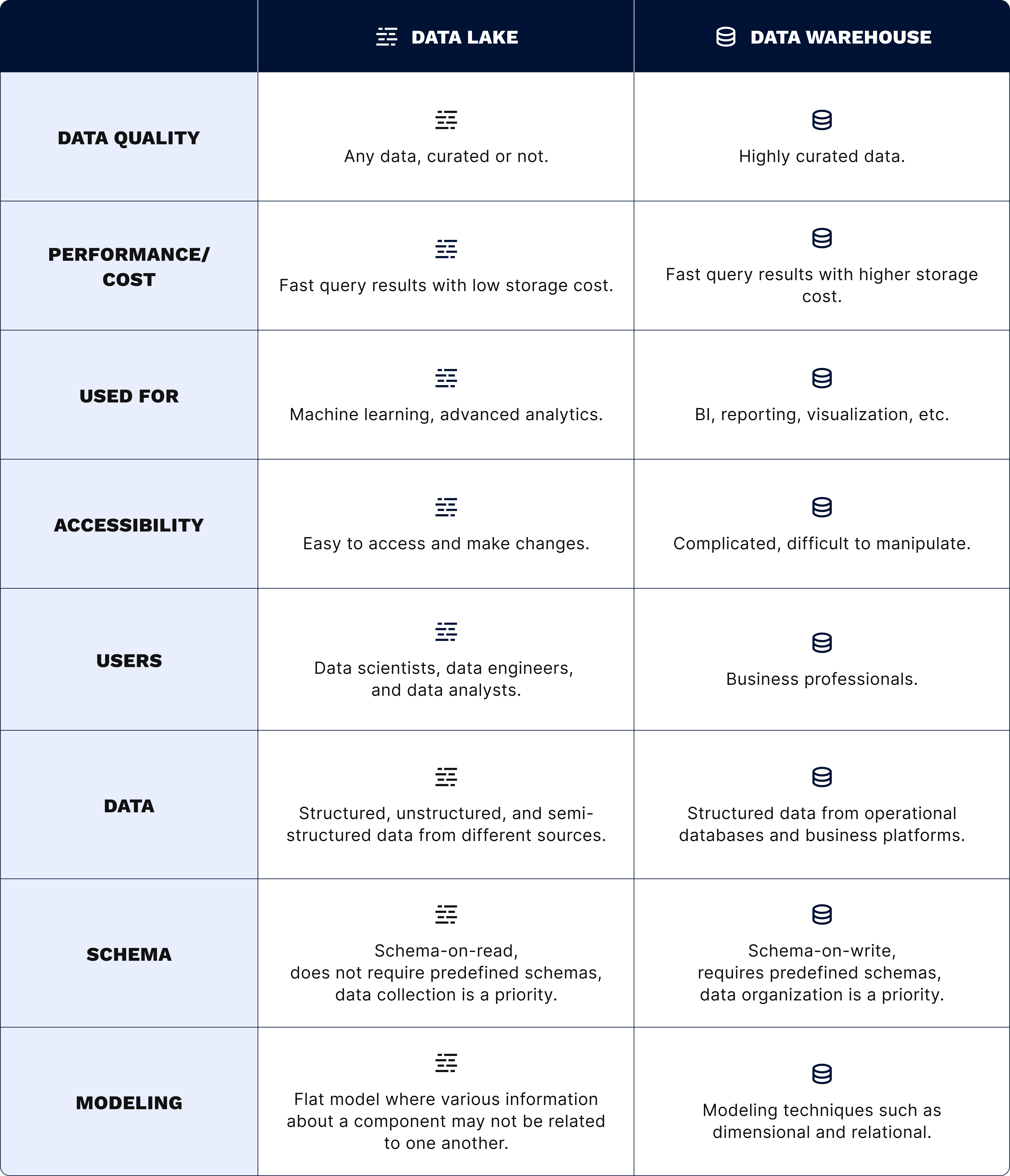
The choice of a database storage is impacted mostly by the type of information that a company accumulates. Given that most organizations store different types of data for different purposes, it can be beneficial to implement both these databases. There are two ways of combining data lakes and data warehouses:
Data lake architecture is the structure in which a data lake is designed, including all the layers, zones, and components. There’s no unified data lake architecture diagram that is suitable and effective for everyone. An enterprise data lake architecture is built according to a company’s objectives and needs. The following are some of the important features of a data lake architecture.
The purpose of this layer is to quickly and effectively consume and store different types of data in its natural and original format from different sources. This layer does not involve any data modification and transformation and is not accessible to end users. It can be composed of different zones, such as landing and conformance.
This zone can also be referred to as an interaction layer. It allows users to access information using SQL and NoSQL queries. The information is obtained from the data lake and displayed for viewing in a consumable form using BI tools, analytics, ML, and other tools.
A data lake can include other zones and layers, such as a sandbox, which can be implemented as a separate environment and as part of a database architecture. A sandbox is mostly designed for advanced analysts and data scientists. Here, they can explore data and create valuable insights.
Data lakes also include additional components that are meant to improve data flow and the processes of working with datasets. They are governance, security, data catalog, ELT processes, archive, master data, stewardship, and more.
There are different stages that data goes through in a data lake, such as distillation and processing.
In the distillation stage, datasets from the raw data are converted into a structured format for further processing and analysis. Raw data is interpreted and transformed into standardized data. The purpose of this stage is to boost performance of data transfer between zones and layers.
This stage involves batch, real-time, or interactive data processing. The most used deployment models are Lambda, which uses separate parallel processing systems, and Kappa, which has a single-stream processing engine. Here, business and analytical applications, as well as AI and machine learning tools, can be employed.
There are two main options for companies on how to implement data lakes: on-premise and cloud.
This is the traditional way of deployment, as data lakes were initially designed for on-premise use. In this case, the software that operates the data lake is installed on the company’s servers. This option requires resource investment into hardware, software license, and staff training for data lake management. With this solution, the company has the full responsibility for security, performance, and upscaling of the system.
This solution implies that the data lake is hosted on a vendor’s hardware and software. This is a more flexible way of deployment compared to on-premise, as it allows companies to upscale and change the size of compute clusters without affecting performance. Security, data protection, and performance rely on the vendor of the cloud data lake platform, which can be advantageous to some companies but pose a disadvantage to others.
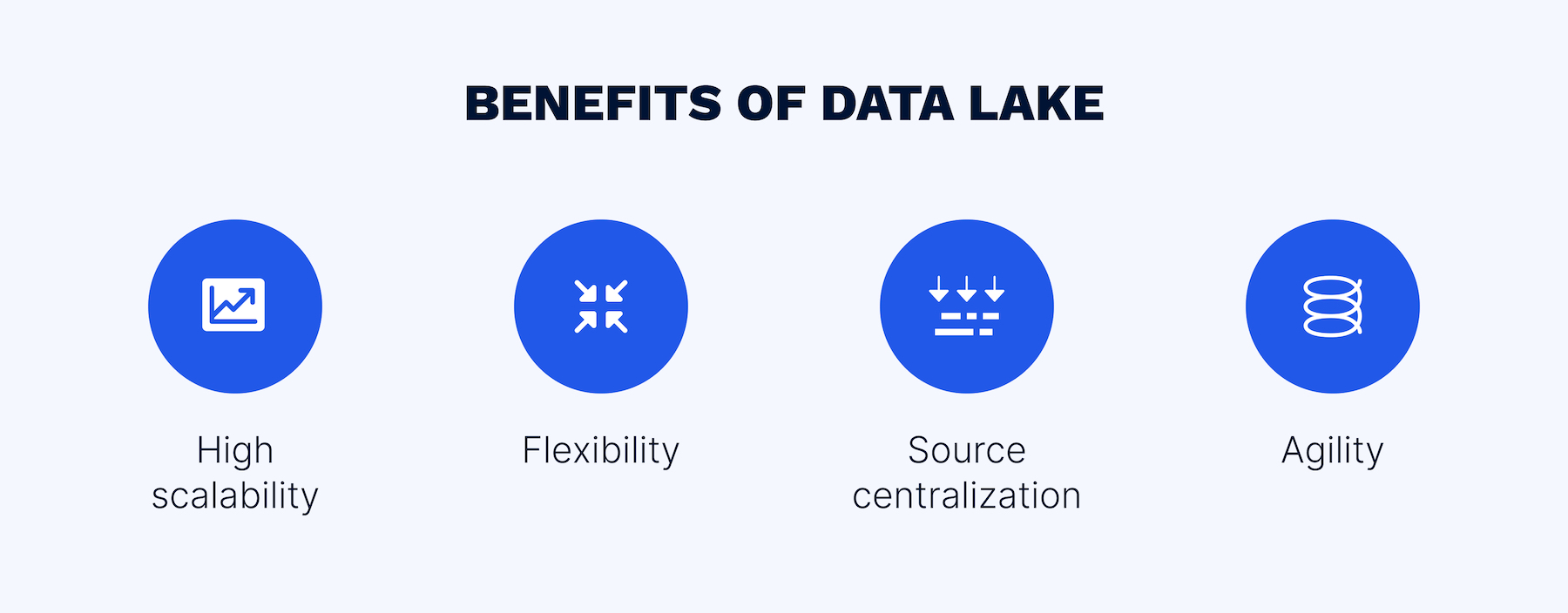
Data lakes can offer many advantages, as long as they are governed effectively.
Data lakes can easily expand and handle a constantly growing amount of information at a relatively low cost compared to data warehouses.
Since data lakes can ingest unstructured, semi-structured, and structured data, all the information is stored in its original form. This can be critical to perform advanced forms of analytics and to teach machine learning models.
In comparison with data warehouses, data lakes can accommodate data from many different sources, making it possible to have a comprehensive analysis of the stored information from different perspectives.
Data lakes are easily configured, enabling various ways of data analysis and allowing companies to quickly adapt to the changing market and economic conditions.
Here are some of the challenges that can impact the productivity of a data lake.
Data lakes require efficient governance to maximize the effectiveness of working with data. Without proper control, a data lake can turn into a data swamp, where any information becomes hard to find.
Security is a major concern for businesses, and an improperly organized security system can lead to serious consequences. Data gets into a data lake from various sources, and, without proper oversight, it can be assigned with inaccurate or insufficient metadata, leading to security breaches.
Data lakes provide an advantageous solution for businesses looking for an effective way to harness, store, and process data. When building a data lake, it’s important to consider the factors that impact performance, such as scalability, security, tools, and technologies for the data lake structure, as well as efficient governance to avoid data swamps.
With an experienced team, it becomes easy to implement a data lake in accordance with a company’s requirements. To learn more about data lakes, contact our data experts.
Blog

























Our team would love to hear from you.
Fill out the form, and we’ve got you covered.
What happens next?
San Diego, California
4445 Eastgate Mall, Suite 200
92121, 1-800-288-9659
San Francisco, California
50 California St #1500
94111, 1-800-288-9659
Pittsburgh, Pennsylvania
One Oxford Centre, 500 Grant St Suite 2900
15219, 1-800-288-9659
Durham, North Carolina
RTP Meridian, 2530 Meridian Pkwy Suite 300
27713, 1-800-288-9659
San Jose, Costa Rica
C. 118B, Trejos Montealegre
10203, 1-800-288-9659

