



















In today’s rapidly evolving digital landscape, data has become an invaluable asset for businesses across all industries. Since organizations continuously generate data from multiple sources, it has become increasingly important to find the right storage solutions to facilitate effective data processing and analysis and prevent the rise of dark data. Among the myriad of data storage options, data warehouses and data lakes have emerged as two of the most popular choices, each catering to different needs and offering distinct benefits. This article provides an overview and comprehensive comparison between data warehouses and data lakes, exploring their unique characteristics and guiding you in determining the most suitable choice for your organization’s IT infrastructure and strategic objectives.
It is important to understand how the data landscape has evolved because the modernization of the data world is having a major impact on how data is constructed, how it is stored, and how it is used to analyze and visualize our ideas and concepts.
This evolution began with the implementation of Relational Database Management Systems (RDBMS), which were designed to house structured data and employ SQL for querying. Despite being reliable and proficient at utilizing SQL capabilities, RDBMS struggled to cope with the increasing volume of information generated by the growth of the internet.
The rise of the internet and its numerous data generation sources resulted in huge flows of decentralized, fragmented data. As a result, it became necessary to consolidate this fragmented data into a single location to derive valuable insights.v
Data warehouses provided the first practical solution to this challenge, offering a unified storage system that served as a single source of truth and delivered a comprehensive view of stored entities. Consequently, data warehouses significantly streamlined the entire data management process.
However, data warehouses presented their fair share of challenges and limitations. They were incapable of storing or processing unstructured data and struggled with real-time data handling. In response to these shortcomings, the concept of big data was formulated. This new paradigm shifted the focus towards distributed architectures capable of providing the necessary flexibility and speed to manage ever-growing data volumes and prompted the implementation of the first data lakes.
Initially, data lakes were designed for on-premises data storage, which led to issues with scaling. To overcome this limitation, the adoption of various cloud technologies became the new focus. While these advancements greatly facilitated data management, other processes, such as building Extract, Transform, and Load (ETL) pipelines and managing data streams, still required considerable effort.
To further optimize data management, businesses turned to cloud platforms offering unprecedented flexibility and efficiency. These platforms revolutionized the data landscape and allowed organizations to harness the full potential of both data warehouses and data lake concepts, catering to varying data management needs in the ever-evolving digital sphere.
With this background in mind, let’s take a closer look at data warehouses and data lakes to provide a basis for further comparison between these two leading data storage concepts.
Most of us are well aware of the importance of data for organizations. However, you may not realize that the raw data gathered from various sources and multiple locations cannot be used directly for analysis. First, it must be integrated and processed to make it suitable for visualization. This brings us to the concept of a data warehouse.
A data warehouse is a central repository where consolidated data from multiple sources is stored. Data warehouses are usually maintained separately from a company’s operational databases, allowing users to access the data whenever they require information. New data is uploaded to the data warehouse on a specified schedule. In summary, a data warehouse:
Since no real-time data capable of changing specific patterns is introduced, the data received from a warehouse is accurate and stable. This stability is invaluable for business users, who can benefit from answering strategic questions and studying trends extracted from the data.
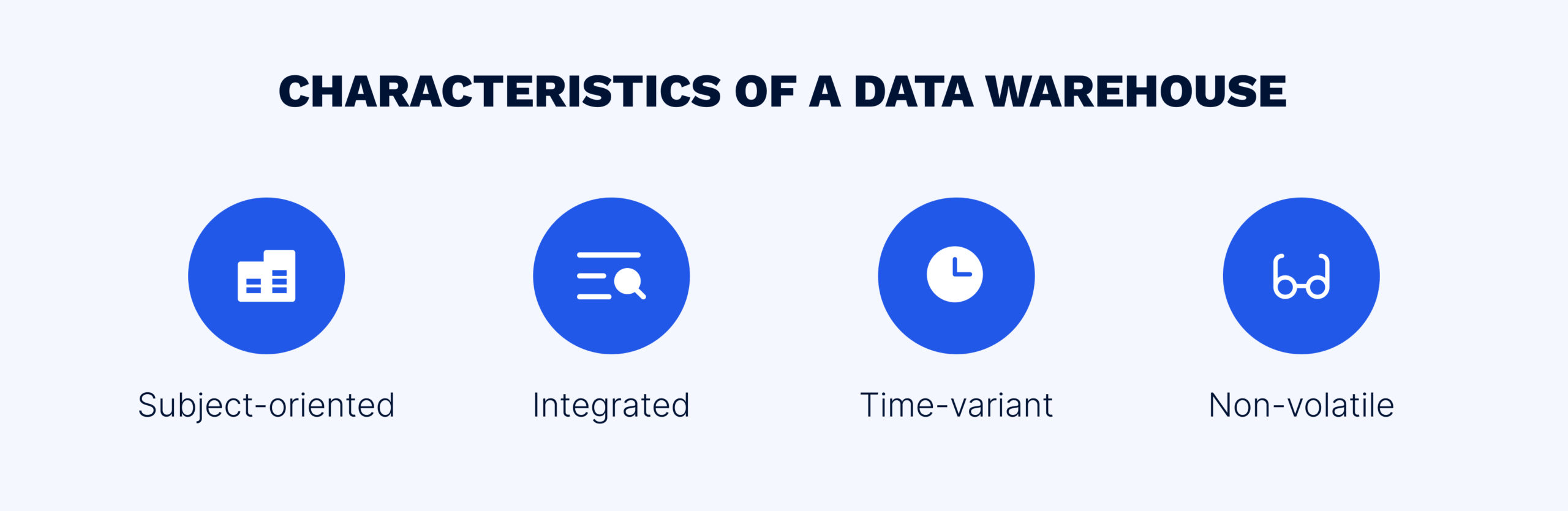
Subject-oriented. Data warehouses provide users with subject-based information (e.g., sales, marketing, logistics) rather than information related to ongoing company operations. This means they provide information on specific subjects, excluding irrelevant data.
Integrated. Data stored in a data warehouse must adhere to consistent naming conventions, formats, and coding. Consistency in these areas helps facilitate effective data analysis.
Time-variant. Data warehouses enable the use of data within an extended period, focusing on historical data. Data can be collected and sorted for a specified timeframe, with the primary keys of data elements containing a component of time, either implicitly or explicitly.
Non-volatile. Data stored in a data warehouse is not overwritten; it is recorded and secured with a read-only attribute. Users can only load and access data, allowing for precise analysis and trend development.
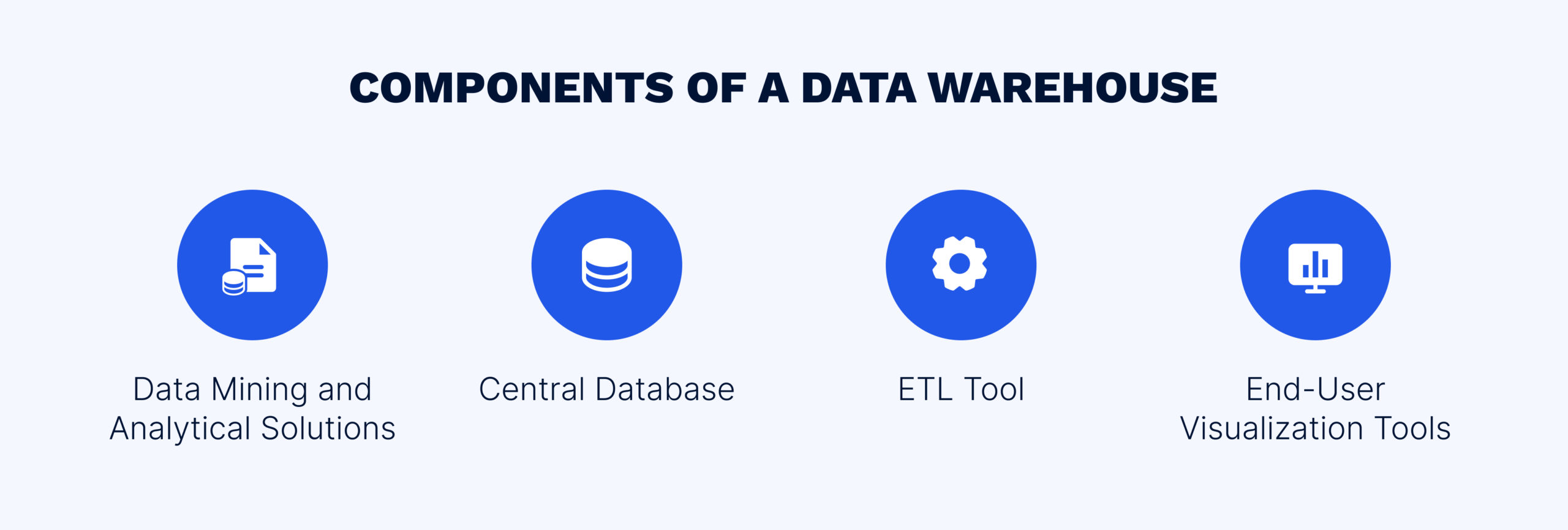
To better understand how a data warehouse is set up, let’s examine the path of data from the data source to the end user. Data enters a data warehouse from various sources, requiring standardization and placement into a common storage area. An ETL pipeline is implemented to standardize the data. Subsequently, data in a unified format is stored in a central database, where it can be accessed by end-users.
Central Databases. The central database is a key component of the data warehouse. Traditionally, databases were built using RDBMS technology. However, RDBMS technology has certain limitations, such as multi-table joins, which can significantly slow down the data extraction process.
In addition, classical RDBMSs store data in a row-oriented format, which can lead to inefficiencies when filtering data as it requires reading the entire contents of a table during the data filtering process. As a result, several new solutions to creating data warehouses have been developed, including the parallel deployment of multiple relational databases (allowing shared memory and scalability) and columnar storage systems optimized for analytical processing.
The ETL Tool. An ETL solution is responsible for preparing data for further analysis by extracting the data from various sources, transforming it according to company requirements, and loading it into the data warehouse.
Business Intelligence Tools. Visualization tools enable end-users to interact with the data, create visual representations, and perform ad-hoc analyses.
The classic data warehouse consists of three logical layers:
Here are two notable examples of data warehouses:
Snowflake. Snowflake is a cloud-based data warehouse solution that offers high scalability, elasticity, and performance. It is designed to handle large volumes of data and provide fast query processing for analytical workloads. Snowflake separates computing and storage, allowing users to scale resources independently. It supports multiple data formats, including CSV, JSON, Parquet, and Avro, and enables seamless integration with popular data integration and visualization tools.
Microsoft Azure Synapse Analytics. This cloud-based data warehousing solution from Microsoft integrates various technologies, including data integration, enterprise data warehousing, big data analytics, and AI capabilities. Azure Synapse Analytics offers scalability, security, and performance improvements over traditional SQL server-based data warehouses. With its ability to handle massive data volumes and provide optimized query performance, this solution enables organizations to efficiently integrate and analyze data from multiple sources. Its integration with the rest of the Azure ecosystem makes it particularly suitable for companies using the Microsoft technology stack.
To conclude, storing large amounts of historical data and conducting in-depth data analyses to generate valuable business insights can be efficiently achieved through the implementation of data warehouses. These repositories provide a highly organized structure that makes it easy for business analysts and data scientists to analyze the data and extract meaningful information.
Having understood what a data warehouse is, we can now take a look at data lakes.
Analyzing and visualizing data is essential for gaining business insights; however, raw data from disparate sources must be consolidated, cleansed, and structured before it can be meaningfully analyzed. The diversity of data sources and types presents a significant challenge to the process of data consolidation. This is where the idea of a data lake comes into play.
A data lake is a centralized and scalable repository that stores both raw and transformed data from multiple sources in its original format. It can store structured, semi-structured, and unstructured data, which makes it ideal for leveraging big data and advanced analytics techniques.
The benefits of data lakes are numerous, so we’ll just name a few. A key advantage is their flexibility in data processing and analytics due to the schema-on-read approach, where data is stored in its original format. This means that users can define the schema they need when reading the data for analysis, allowing for greater flexibility.
Another advantage of data lakes is their scalability. They can accommodate growing data volumes, which ensures efficient storage and processing capabilities. This feature is particularly useful for companies that deal with large amounts of data. Data lakes also offer an agile environment for data exploration, analysis, and machine learning while offering robust security measures that include data encryption, access control, and audit logging, ensuring data privacy and compliance with regulations.
Understanding the structure of a data lake requires an examination of the data journey from the source to the end user. This path comprises several essential components:
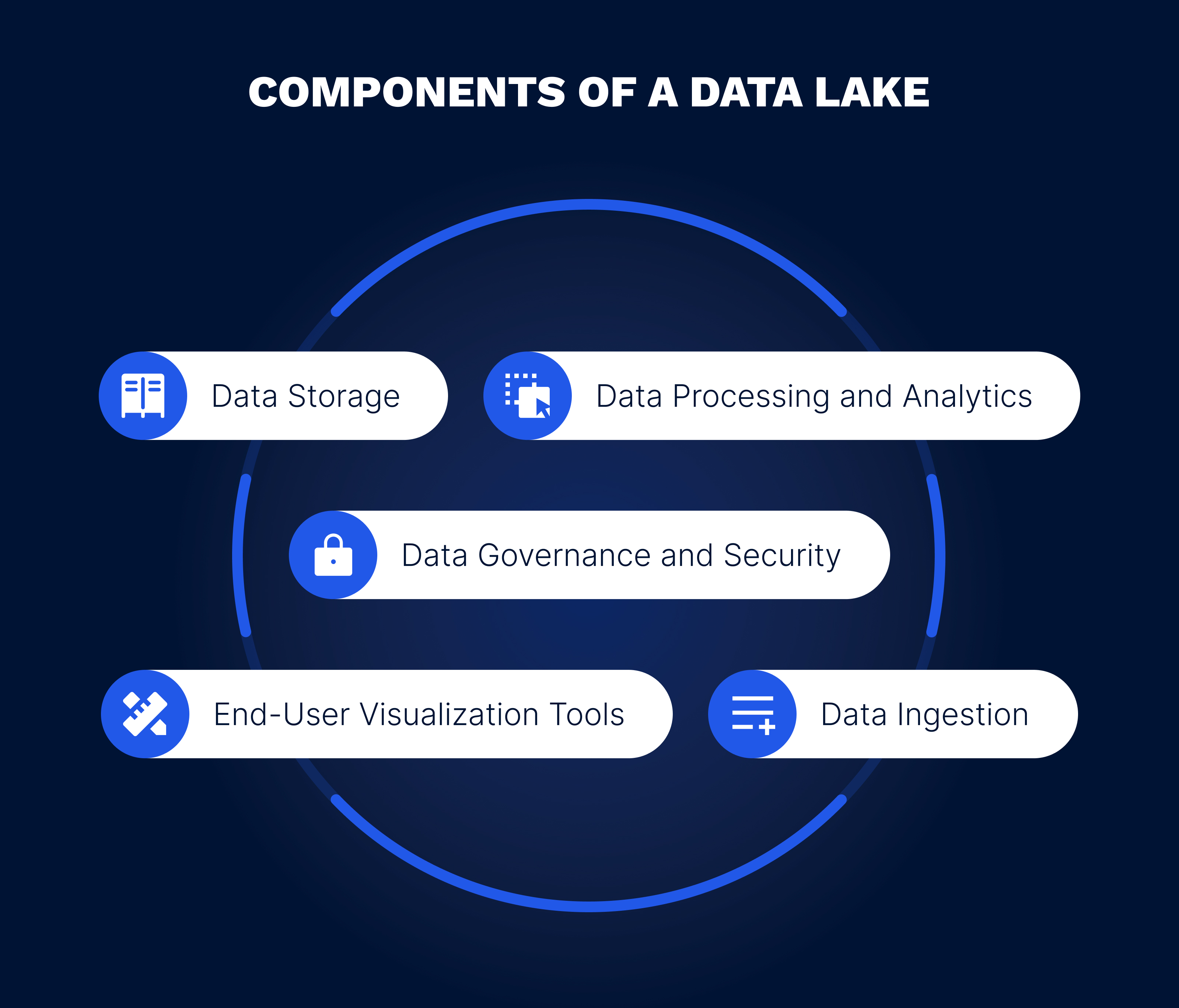
Data ingestion. This component involves the collection and import of data from various sources into the data lake, which can occur in real time, in batches, or as a combination of both.
Data storage. This refers to the location where raw data in its original format is stored, along with processed and transformed data. Typically, data lakes use distributed storage systems such as the Hadoop Distributed File System (HDFS) or cloud-based storage services.
Data processing and analytics. These are the tools that enable organizations to analyze data, uncover patterns, and generate insights. They can include distributed processing frameworks such as Apache Spark and Apache Flink, machine learning libraries, and specialized analytics engines.
End-user visualization tools. These tools offer a user-friendly interface for end-users to interact with and visualize the data.
Data governance and security. This component ensures that data privacy, compliance, and proper data management practices are maintained within the data lake.
Data lake architecture employs a multi-layered approach and follows certain principles. Data is ingested from sources and stored in the raw data store layer. This data is then transformed and processed in a separate layer before being utilized for traditional or advanced analytics in the insights layer.
Different user personas can access the data in the consumer layer, while common services like monitoring and security are employed across all layers. DevOps practices are incorporated for continuous integration, delivery, testing, and deployment across various environments.
Designing data lakes properly requires asking fundamental questions and prioritizing use cases. When designing a cost-efficient and flexible data lake architecture, the following best practices should be observed:
Here are two prominent examples of the many tools used to create data lakes:
Amazon S3. Amazon Simple Storage Service (S3) is a popular data lake solution provided by Amazon Web Services. It allows organizations to store large amounts of data in an object-based storage system. Amazon S3 supports multiple data formats, including CSV, JSON, Parquet, and more. The service offers high durability and availability, making it suitable for data archiving, data lakes, and big data analytics. With its scalability, security features, and compatibility with a wide range of data processing tools, Amazon S3 is a popular choice for building data lakes.
Hadoop Distributed File System. HDFS is an integral part of the Apache Hadoop ecosystem and is widely used for building data lakes. It is a distributed file system that can store massive amounts of data across multiple servers in a Hadoop cluster. HDFS is fault-tolerant and highly scalable, making it an ideal choice for handling large data workloads. It supports multiple file formats and provides features such as data redundancy, data replication, and data compression that contribute to high data availability and efficiency. Many organizations use HDFS to build data lakes and perform advanced analytics on the stored data.
Based on the information above, we can now compare the following key factors of the two data storage options to help you make the right choice and highlight the differences between data warehouses and data lakes.
Data types. Data warehouses are designed to store structured data only. This means that the data must have a pre-defined structure that remains stable over time. On the other hand, data lakes allow for the collection of unstructured data, as well as structured data.
Data processing requirements. Data lakes offer the advantage of housing raw data with all metadata, which can be analyzed with the help of a schema applied at the moment of extraction. This means that data can be transformed and analyzed in a flexible way. In contrast, data warehouses require ETL processes to transform unstructured data into data with a pre-defined structure before it can be analyzed.
Resources and storage constraints. Data warehouses require significant resources to process and analyze data, which can make it a more expensive option. Storage costs can also increase with increasing volume and velocity. Data lakes, on the other hand, can store data in its raw form, making it a more cost-efficient option.
End-user needs. The role and duties of the end user define the type of data storage that is most appropriate for the organization. If the primary use case is business insights and reporting for the operations team, a data warehouse may be the better option. However, if a data scientist wants to utilize AI algorithms and access both structured and unstructured data, a data lake may be preferred. Technology and Data Ecosystem. Organizations differ in their attitudes to trusting open-source software. Data lakes are popular because of the widespread adoption of Hadoop and the rise in unstructured data from various systems used across companies and real-time data streams. Changes are simple with a data lake compared to the more costly process of updating the relational database of a data warehouse.
In summary, both data lakes and data warehouses play an integral role in data management although they differ in their variety of applications and adaptability. Data lakes, with their unstructured nature, offer a broader range of analytics, making them best suited for big data and AI applications. On the other hand, data warehouses provide structured, filtered data, which is perfect for organizations looking for targeted data analysis and reporting. The choice ultimately depends on the unique needs of your company, with the further understanding that both systems can co-exist, complementing each other to maximize the value derived from comprehensive data analytics.
With the right team in place, implementing a data warehouse can be a smooth and efficient process that delivers significant benefits to businesses of all sizes. To learn more about how a data warehouse can help your organization, contact our team of data experts today.
Blog

























Our team would love to hear from you.
Fill out the form, and we’ve got you covered.
What happens next?
San Diego, California
4445 Eastgate Mall, Suite 200
92121, 1-800-288-9659
San Francisco, California
50 California St #1500
94111, 1-800-288-9659
Pittsburgh, Pennsylvania
One Oxford Centre, 500 Grant St Suite 2900
15219, 1-800-288-9659
Durham, North Carolina
RTP Meridian, 2530 Meridian Pkwy Suite 300
27713, 1-800-288-9659
San Jose, Costa Rica
C. 118B, Trejos Montealegre
10203, 1-800-288-9659

